Formale Sprachen
Natürliche Sprachen vs. formale Sprachen
Wenn sich zwei Geschäftspartner verstehen sollen, müssen sie eine gemeinsame Sprache sprechen. Natürliche Sprachen sind oft mehrdeutig und variantenreich und daher im Allgemeinen zur präzisen Kommuni-kation ungeeignet.
Zur direkten Verständigung mit Maschinen verwendet man daher in der Regel formale Sprachen, die als eindeutig definierte Menge zugelassener Zeichenketten bzw. Sequenzen festgelegt werden.
Zeichen und Wörter

Anja kocht leidenschaftlich gern. Für die Zubereitung eines Kartoffelgratins muss laut Rezept der Backofen dazu gebracht werden, den Umluftgrill einzuschalten und das Gericht 1h und 15min lang bei 160° zu garen. Außerdem soll das Essen um Punkt 12.30h fertig sein. Dazu muss dem Backofen mitgeteilt werden
- wie lange die Garzeit,
- wie hoch die Temperatur,
- wann das Gericht fertig sein soll und
- welche Heizart verwendet werden soll.
Bei modernen Backöfen verwendet man hierzu spezielle Druck- und Drehknöpfe, an denen verschiedene Symbole angebracht sind. Die Heizdauer (bzw. Ausschaltzeit) kann etwa durch Drücken des Symbols 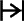 (bzw.
(bzw. 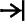 ) mit jeweils anschließender Eingabe von maximal 4 Ziffern, die Heizart durch eines der 5 Symbole
) mit jeweils anschließender Eingabe von maximal 4 Ziffern, die Heizart durch eines der 5 Symbole
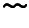 ,
, ,
,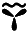 ,
, bzw.
bzw. - 0 für "aus"
und die Temperatur durch eine Zahl aus drei Ziffern zwischen 000 und 299 angegeben werden (siehe Bild).
Mögliche Zeichen für die Verständigung mit dem Backofen sind also die Ziffern 0, 1, 2, 3, 4, 5, 6, 7, 8 und 9 sowie die Symbole , , , , und . Durch das Wort 115230160 wird der gewünschte Ablauf zum Garen des Kartoffelgratins beschrieben.
Formale Sprachen
Nicht alle möglichen Kombinationen von Zeichen eines Alphabetes bilden korrekte Wörter einer bestimmten Sprache. Durch die Angabe formaler Regeln wird die Menge aller zulässigen Zeichenketten als
formale Sprache
definiert. Am Beispiel des oben beschriebenen Backofens lauten die Regeln für die Bildung von Wörtern wie folgt:- Auf jedes der Zeichen bzw. müssen jeweils ein bis vier Ziffern aus 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 folgen.
- Genau eines der Zeichen , , oder gefolgt von einer Kombination aus einer der Ziffern 0, 1, 2 mit zwei Ziffern aus 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 muss enthalten sein.
Syntax und Semantik
Die Gesamtheit der Regeln, in denen festgelegt wird, welche Zeichenketten zu einer Sprache gehören, bezeichnet man als Syntax dieser Sprache. In der oben beschriebenen Sprache ist z. B. die Zeichenkette 999999 syntaktisch falsch, da die Regeln der Sprache nicht eingehalten werden. Dagegen erhält man mit 8769897234 ein nach obigen Regeln syntaktisch korrekt gebildetes Wort.
Obwohl die Syntax des Wortes 8769897234 korrekt ist, das Wort also zur oben definierten Sprache gehört, ist eine sinnvolle Interpretation hier nicht möglich, da 876 und 9897 nicht als Uhrzeit verstanden werden können. Allgemein gibt die Semantik einer Zeichenkette die Bedeutung dieses Wortes wieder. Nach Austausch einiger Ziffern erhält man mit 1161817234 ein Wort, dessen Semantik umgangssprachlich mit „1 h und 16 min lang wird die Grilltemperatur auf 234 °C gestellt, sodass um 18.17 Uhr der Backvorgang beendet ist“ beschrieben werden kann.
Das bisschen Haushalt . . .
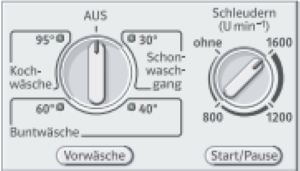
Gesucht ist eine formale Sprache für die Bedienung einer Waschmaschine. Betrachte dazu das dargestellte Bedienfeld.
- Gib ein mögliches Alphabet an.
- Formuliere die formalen Regeln für Wörter der Waschmaschinen-Sprache.
- Alphabet: 30°, 40°, 60°, 95°, Aus, ohne, 800, 1200, 1600, Vorwäsche und Start/Pause.
-
Individuelle Lösungen, zum Beispiel:
- Ein Wort kann nur aus dem Zeichen Vorwäsche bestehen.
- Ansonsten besteht ein Wort aus einer Kombination von 30°, 40°, 60°, 95° gefolgt von mindestens einmal Start/Pause.
- Die Wörter aus können zusätzlich noch ohne, 800, 1200 oder 1600 enthalten, sofern geschleudert werden soll.
- 95° 800 Start/Pause
- 30° Start/Pause Start/Pause Start/Pause
- Vorwäsche
Eine einfache Mathematik-Sprache
Formuliere die Regeln einer formalen Sprache, durch die mithilfe der Zeichen (, ), +, –, ·,: und den Ziffern 0, 1, . . ., 9 syntaktisch korrekte Rechenterme beschrieben werden können. Diese sollen nur die vier Grundrechenarten inklusive Klammerung enthalten.
- Eine Ziffer ist eines der Zeichen 0,1,2,3,4,5,6,7,8,9.
- Eine Zahl besteht entweder aus einer Ziffer oder aus einem Zeichen aus 1,2,3,4,5,6,7,8,9 gefolgt von beliebig vielen Ziffern.
- Zwischen zwei Zahlen darf ein Rechenausdruck +, –, · oder : stehen, dies ergibt einen Term.
- Vor einem Term kann das Zeichen ( stehen. Dann muss nach dem Term das Zeichen ) stehen.
Formale Sprachen als Mengen
Zeichnen von Pflanzen
Ein Zeichenprogramm verfügt über einen programmierbaren Stift. Dieser kennt die folgenden Befehle:
- F: Zeichne eine kurze Linie von deiner aktuellen Position nach vorne.
- -: Drehe dich ein wenig nach rechts.
- +: Drehe dich ein wenig nach links.
- [: Merke dir die augenblickliche Position und Richtung.
- ]: Kehre zur letzten gemerkten Position und Richtung zurück.
Dann ist F[+FF][--F]F[+F[+FF][--F]FF[+FF][--F]F][--F[+FF][--F]F]F[+FF][--F]F ein Wort der formalen Sprache der künstlichen Pflanzen \(L_{Pflanzen}\) und erzeugt das Bild:
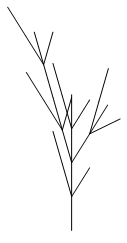
Baum zeichnen
Erstelle eine Pflanze, welche in der formalen Sprache \(L_{Pflanzen}\) enthalten ist. Erstelle die Zeichnung und das passende Wort der Sprache jeweils auf einem eigenen Zettel.
Tauschen
- Suche dir einen Mitschüler oder eine Mitschülerin die ebenfalls an dieser Station arbeitet.
- Tauscht nun untereinander eure Worte / Zeichenkette aus, nicht die Zeichnung.
- Jeder zeichnet alleine die Pflanze des Partners anhand des erhaltenen Wortes.
- Vergleicht die Ergebnisse und diskutiert gegebenenfalls wo es Unterschiede gibt und warum.
Im Grunde habt ihr Grade Worte der eine Sprache \(L_{Pflanzen}\) erzeugt. Da die Sprache L aus allen möglichen sinnvollen Kombinationen besteht, kann diese als Menge dieser Wörter aufgefasst werden.
\(L_{Pflanzen}=\{F,FF,FFF,F+F,F-F,FF+F,FF-F,…\}\)
Formale Sprachen als Mengen
Formale Sprachen sind Mengen, welche bestimmte Wörter bestehend aus den Zeichen eines Alphabets \(\Sigma\) (gr. Sigma) enthalten. Diese Menge wird mit L (Abkürzung für language) bezeichnet und enthält alle Worte, welche zu dieser formalen Sprache gehören.
\(L=\{w_1,w_2,w_3,…\}\)
Häufig enthalten formale Sprachen unendlich viele Wörter. Um dennoch die Sprache beschreiben zu kön-nen verwendet man Mengen mit Bedingungen.
\(L=\{w |\) w erfüllt bestimmte Bedingungen \(\}\)
Betrachtet man diese Ansammlungen von Wörtern, so ergeben sich zwei Kernfragen:
- Ist ein gegebenes Wort in der formalen Sprache enthalten. Dies wird als Wortproblem bezeichnet.
- Gibt es ein gemeinsames Muster in den Wörtern der formalen Sprache und wie lässt sich das zur Darstellung der Sprache nutzen. Dies wird später im Bereich Automaten / Grammatik vertieft.
Beispiel 1: Wortproblem und die Pflanzensprache
Bezogen auf obiges Beispiel stellt sich die Frage, ob das Wort FF---[[ in der Sprache \(L_{Pflanzen}\) enthalten ist?
Hier ist die Antwort recht simpel: Ja. Denn die Menge \(L_{Pflanzen}\) besteht aus allen möglichen Aneinanderreihungen (auch Konkatenationen genannt) der Zeichen aus dem Alphabet \(\Sigma=\{F,-,+,[,]\}\). Das Alphabet wird üblicherweise mit dem griechischen Buchstaben \(\Sigma\) (Sigma) bezeichnet und die Zeichen sind in diesem Fall die erlaubten Operationen des Zeichenprogramms F, -, +, [ und ]. Ein kurzer Blick genügt, um zu überprüfen, dass FF---[[ nur aus diesen Zeichen besteht.
Beispiel 2: Wortproblem mit Bedingungen
Das Wortproblem ist schwieriger, wenn an die Wörter einer formalen Sprache Bedingungen gestellt werden, wobei das Alphabet \(\Sigma=\{a,b\}\) ist:
\(L=\{w |\) w beginnt mit aba UND w enthält nie die Zeichenfolge bb \(\}\)
d.h. in der formalen Sprache L sind alle Wörter, also Konkatenationen der Zeichen des Alphabets, enthalten, welche die beiden Bedingungen erfüllen, dass sie mit aba beginnen und nie die Zeichenfolge bb ent-halten. Man spricht den Strich als „für die gilt“. Hier: Die Menge L enthält alle Wörter w für die gilt, w beginnt mit aba und w enthält nie die Zeichenfolge bb.
Das Wortproblem
Entscheide, ob w in der formalen Sprache L ist. Das Alphabet ist \(\Sigma=\{a,b\}\).
- \(L=\{w |\) w endet auf ab \(\}\) und w=ab
- \(L=\{w |\) w enthält das Teilwort abba \(\}\) und w = abababaaabababbabbbb
- \(L=\{w |\) w enthält mehr a’s als b’s \(\}\) und w = aaabbabababbba
- Ja, w ist in L enthalten.
- Ja, w ist in L enthalten.
- Nein, w ist nicht in L enthalten. Es sind jeweils 7 a's und b's.
Mengen mit Bedingungen: E-Mails
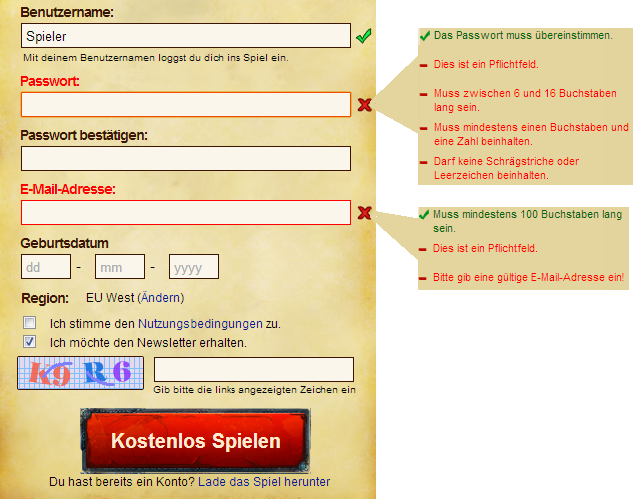
Oben siehst du ein typisches Login-Formular für Internetseiten oder Spiele. Die gültigen Passwörter bzw. E-Mail-Adressen haben ein bestimmtes Muster. Daher bilden alle gültigen Passwörter bzw. alle gültigen E-Mail-Adressen jeweils eine formale Sprache
- Stelle die Sprache der gültigen Passwörter als Mengen mit Bedingungen dar. Tipp: Mehrere Bedingungen können einfach als L={ w | Bedingung1 und Bedingung2 …} notiert werden.
-
Entscheide begründet, ob die folgenden Wörter in der Sprache der gültigen Passwörter enthalten sind.
- Test123
- Hallo
- 1337!!
- BaumPferdHase123
- Ich bin Dumm
- a1.+-*/
- L = { w | w hat mindesten 6 Zeichen und w hat maximal 16 Zeichen und w enthält mindestens eine Zahl und w enthält mindestens einen Buchstaben und w enthält keine Schrägstriche und w enthält keine Leerzeichen} (Alternative Lösungen möglich)
-
- Ja
- Nein, es ist keine Zahl vorhanden.
- Nein, es ist kein Buchstabe enthalten.
- Ja
- Nein, Leerzeichen sind untersagt.
- Nein, der Schrägstrich ist nicht erlaubt. Ansonsten wäre a1.,+-* erlaubt.
Automaten als Graph
Der Yoga-Automat
Beim Yoga nimmt man nacheinander verschiedene Positionen ein. Man verweilt in einer Position, bevor man vom Yogalehrer aufgefordert wird, in die nächste Position zu wechseln. In dieser Position verharrt man wieder, bis die nächste Anweisung erfolgt, etc.
Beispielsweise könnten die Anweisungen des Lehrers wie folgt lauten:
- „Wir starten nun in der Grußposition.“ (Position 1)
- „Nehmt nun die Arme über den Kopf und nehmt die Position 2 ‚Gruß an die Sonne‘ ein.“
- „Hebt ein Bein und nehmt die Position 5 ‚Gruß an den Flamingo‘ ein.“
- „Stellt das Bein wieder ab und grüßt die Sonne.“ (Position 2)
- „Nehmt die Arme wieder zur Brust.“ (Position 1)
Dargestellt werden kann dieser Ablauf auch in einer Zeichnung – in einem Graphen – in dem noch weitere Positionen und Anweisungen dargestellt sind:
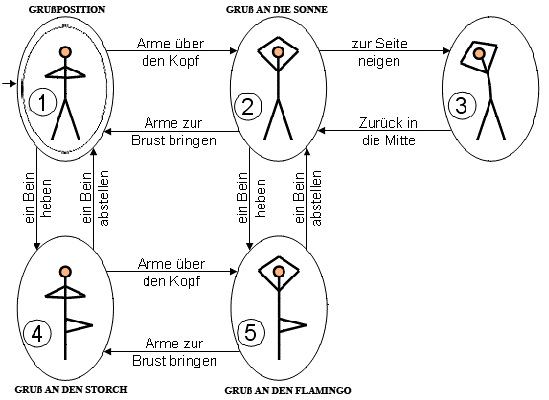
Yoga-Automat komplett
Betrachte den Graphen der Yoga-Stunde nochmal genau und vervollständige die oben stehenden Anweisungen des Yogi-Lehrers, so dass jede Position mindestens einmal eingenommen wird!
Beispiel:
- „Wir starten nun in der Grußposition.“ (Position 1)
- „Nehmt nun die Arme über den Kopf und nehmt die Position 2 ‚Gruß an die Sonne‘ ein.“
- „Neigt euren Oberkörper zur Seite“ (Position 3)
- „Neigt euren Oberkörper nun wieder zur Mitte und grüßt die Sonne“ (Position 2)
- „Hebt ein Bein und nehmt die Position 5 ‚Gruß an den Flamingo‘ ein.“
- „Stellt das Bein wieder ab und grüßt die Sonne.“ (Position 2)
- „Nehmt die Arme wieder zur Brust.“ (Position 1)
- „Hebt ein Bein und nehmt die Position 4, „Gruß an den Storch“ ein.“
- „Nehmt die Arme über den Kopf und grüßt den Flamingo“ (Position 5)
- „Nehmt die Arme wieder zur Brust und grüßt nochmals den Storch“ (Position 4)
- „Stellt das Bein wieder ab und geht in die Anfangsposition (Position1) wieder zurück. Hier endet unsere Yogastunde.“
Automaten in der Informatik
Geregelte Abläufe aus dem Alltag lassen sich in der Informatik als Automaten beschreiben. Einen Automaten kann man sich als eine Art „Maschine“ vorstellen, die stur einem festgelegten Schema folgt, so wie in unserem Beispiel der Yoga-Kurs.
Dieser kann sich in verschiedenen Zuständen befinden (Grußposition, Gruß an den Storch, geneigt, …). Das festgelegte Schema besagt, dass man nach „ein Bein heben“ und anschließendem „Arme über den Kopf“ im Zustand „Gruß an den Flamingo“ landet.
Im allgemeinen haben alle Automaten ein solches festes, vorgegebenes Schema wie zum Beispiel der „Yoga-Automat“.
Automaten setzten sich zusammen aus Zuständen und Übergängen. Ein festgelegtes Schema gibt vor, wann ein Automat von einem Zustand in einen anderen Zustand übergeht. Ein Automat kann sich dabei zu jedem Zeitpunkt nur in genau einem Zustand befinden.
Solche festgelegten Schemata können mit Hilfe von Zustandsübergangsdiagrammen zeichnerisch dargestellt werden. Kreise stellen darin die Zustände dar. Die möglichen Übergänge von einem Zustand in einen anderen werden durch Pfeile markiert. Der Startzustand, also der Zustand, in dem sich der Automat zu Beginn des Vorgangs befindet, wird mit einem Start gekennzeichnet.
Automaten als Graphen
Eine übersichtliche Darstellung der Zustände und Übergange ist die Darstellung des Automaten als Graph.
| Automat | Symbol | Beispiel aus Yogalektion |
|---|---|---|
| Zustand |  |
Der Yogi befindet sich in einer Position. |
| Eingabe bzw. Eingabezeichen | Zeichen des Eingabealphabets. In der Regel Kleinbuchstaben a,b,c… oder Zahlen 1,2,3,… | Anweisungen des Yogi, z.B. „Arme über den Kopf nehmen“. |
| Zustandsübergang |  |
Pfeil mit der Beschriftung „Arme über den Kopf “. |
| Startzustand (pro Automat eindeutig) |  |
Die Yogis beginnen mit den Übungen immer in der Grußposition. |
| Endzustand (ein Automat kann mehrere haben) |  |
Die Yogis beenden ihre Übungen immer in der Grußposition.(In dem Beispiel ist der Startzustand somit gleichzeitig auch der Endzustand). |
Automaten mit Endzuständen bezeichnet man als Akzeptoren. Diese entscheiden für eine Folge von Eingabezeichen, ob diese akzeptiert wird oder nicht.
Automaten ohne Endzustände bezeichnet man als Transitionssysteme. Diese wickeln nur ihre Zustandsübergänge ab und ermöglichen so die Darstellung realer Automaten als einfaches Modell. Hierbei werden für Zustandsbezeichnungen wie \(q_0\) bzw. für die Eingabezeichen häufig sinnvolle Bezeichnung und Beschreibungen verwendet.
Beispiel eines Transitionssystems

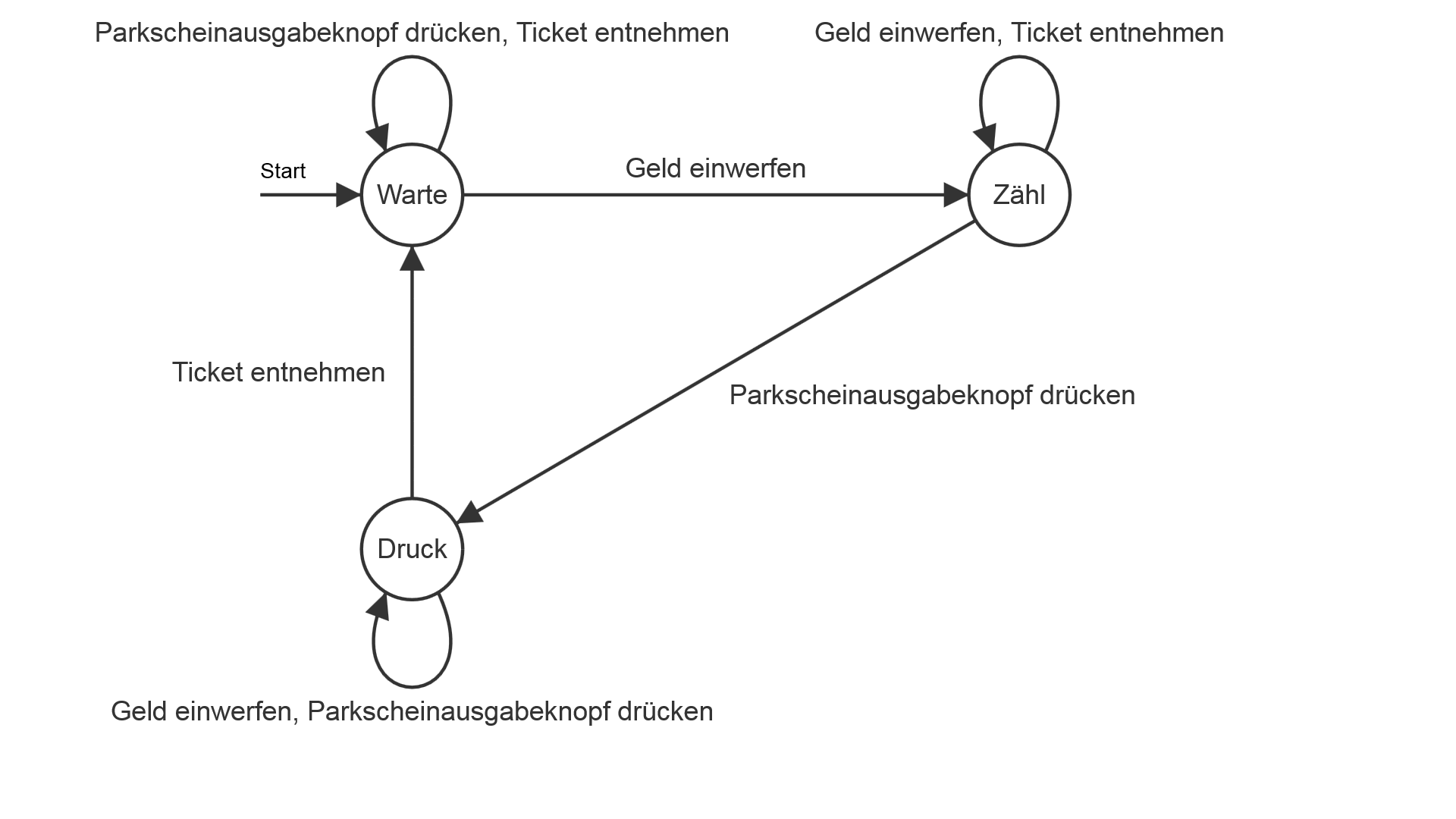
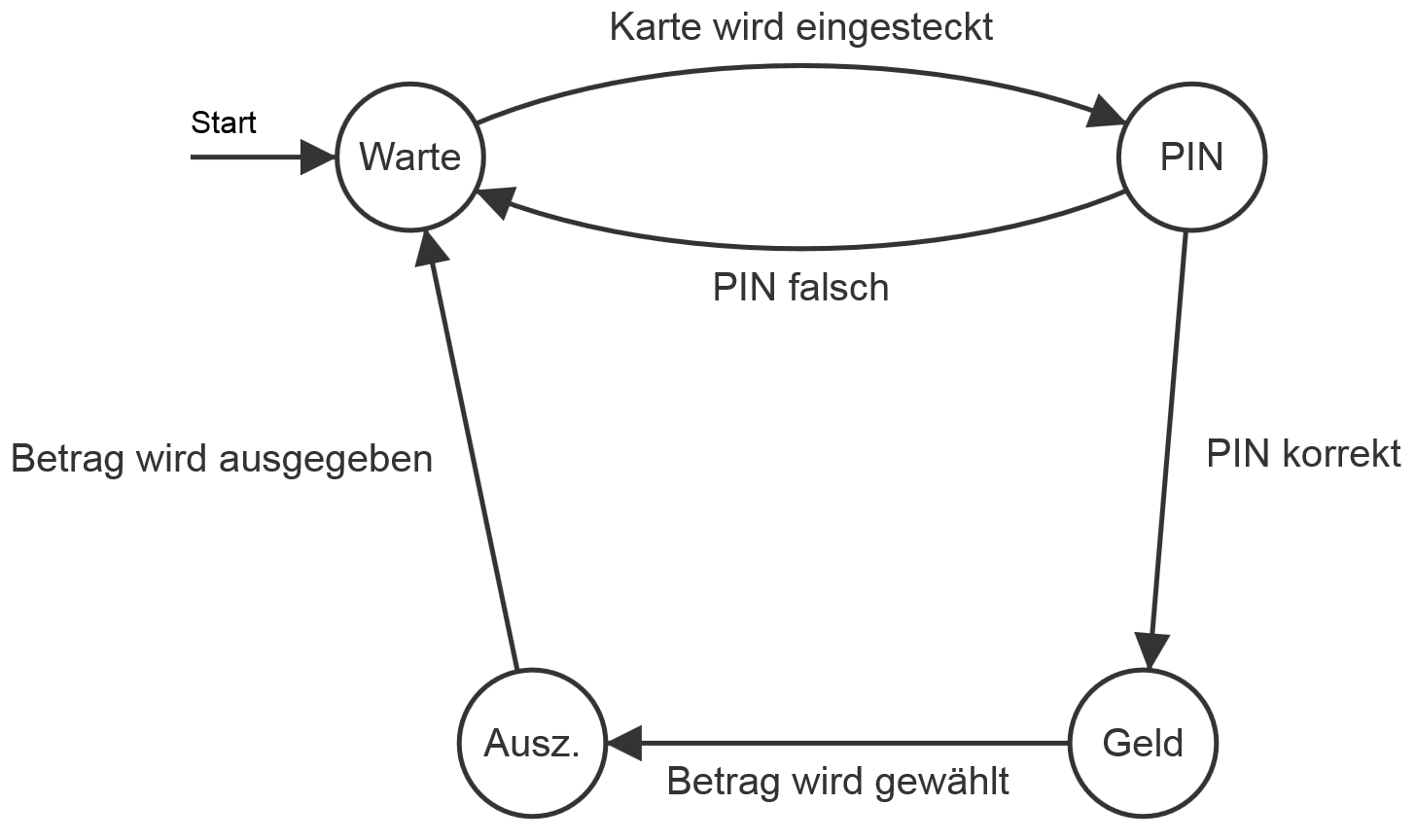
Es soll ein Modell für einen Parkscheinautomat entworfen werden.
- Am Anfang zeigt der Parkautomat immer 0 Minuten an und wartet, bis jemand Geld einschmeißt.
- Dann zählt der Automat die Parkminuten. Solange jemand weiter Geld einschmeißt ohne den Parkscheinausgabe-Knopf zu drücken, zählt der Automat weiter Parkminuten.
- Irgendwann drückt jemand den Parkscheinausgabe-Knopf. Dann soll der Parkscheinautomat das Parkticket drucken und ausgeben.
- Wurde das Ticket entnommen, so gelangt der Automat wieder in die Wartestellung.
Der Automat besitzt somit drei Zustände:
- einen Wartezustand, welcher gleichzeitig der Startzustand ist.
- einen Zustand "Zähl", der die Parkminuten zählt, solange Geld eingeworfen wird.
- einen Zustand "Druck", der auf Knopfdruck den Parkschein ausgibt und solange wartet bis das gedruckte Ticket entnommen wurde.
Die Eingabezeichen, das sogenannte Eingabealphabet \(\Sigma\), sind hier die möglichen Eingaben durch einen Benutzer:
- Geldstück einwerfen
- Parkscheinausgabeknopf drücken
- Ticket entnehmen
Geldautomat
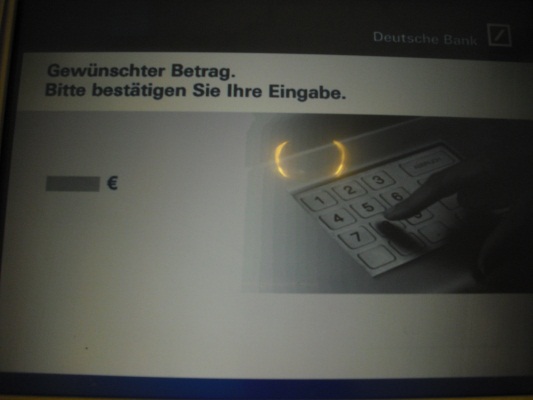

- Stelle dir vor, du möchtest den Betrag von 50€ mit Hilfe deiner EC-Karte von deinem Konto abheben. Wie würdest du vorgehen? Notiere die einzelnen Schritte.
- Zeichne ein Zustandsübergangsdiagramm für den Geldautomat.
- Individuelle Lösung
Automaten als Tabelle
Lichtschalterautomat
Viele Dinge des täglichen Lebens lassen sich als ein Automat auffassen, welcher verschiedene Zustände einnehmen kann. Betrachte dazu einen Lichtschalter, welcher eine Lampe im Raum an- oder ausschalten kann.
Wenn ich kein Licht im Zimmer habe, dann erreiche ich durch das Drücken des Schalters, dass das Licht eingeschaltet wird. Drücke ich den Schalter erneut geht das Licht wieder aus. Demnach kann der Automat zwei Zustände annehmen, die hier mit „Licht“ oder „Kein Licht“ bezeichnet werden. Um zwischen diesen Zuständen zu wechseln, erfordert es eine entsprechende Aktion (hier Lichtschalter drücken) bzw. in der Sprache der Automaten, eine entsprechende Eingabe. Die Aktionen werden auch als Übergänge bezeichnet.
In Kürze:
Wenn das Licht aus ist und der Schalter gedrückt wird, dann geht das Licht an.
Wenn das Licht an ist und der Schalter gedrückt wird, dann geht das Licht aus.

Die Zustandsübergangsfunktion als Tabelle
Obiges Beispiel zum Lichtschalter lässt sich kurz und für eine Maschine verständlich in eine Tabelle über-tragen. Ob man als Mensch Automaten lieber als Tabelle oder Graph darstellt ist Geschmackssache.
| \(\delta(q,x)\) | Kein Licht | Licht |
|---|---|---|
| Drücken | Licht | Kein Licht |
Diese Tabelle kann so interpretiert werden: Die Spaltenüberschriften sind die möglichen Zustände des Au-tomaten, hier „Kein Licht“ und „Licht“. Am Anfang der Zeilen stehen die möglichen Eingaben bzw. Aktionen, wobei hier nur das Drücken des Schalters eine gültige Eingabe darstellt. In den Zellen befinden sich dann die Übergänge, also zum Beispiel das aus dem Zustand „Kein Licht“ nach der Aktion „drücken“ der Automat in den Zustand „Licht“ übergeht.
Darf es auch etwas formaler sein? Aber Ja!
Automaten setzen sich zusammen aus Zuständen und Übergängen. Ein festgelegtes Schema gibt vor, wann ein Automat von einem Zustand in einen anderen Zustand übergeht.
Ein Automat kann sich dabei zu jedem Zeitpunkt nur in genau einem Zustand befinden. Übergänge werden anhand einer Übergangsfunktion beschrieben. Eine Übergangsfunktion gibt an, mit welchem Zeichen von einem bestimmten Zustand in einen anderen gewechselt werden kann.
Diese Übergänge können als Tabelle dargestellt werden, z.B.:

Die Übergangsfunktion kann wie eine mathematische Funktion verstanden werden. Die Tabelle stellt die Funktionswerte einer Funktion \(\delta(q,x)\) dar. Die Funktion hängt dabei von den beiden Variablen q für den aktuellen Zustand und x für das aktuelle Eingabezeichen der Eingabesequenz ab. Die obenstehende Tabelle kann also auch folgendermaßen notiert werden:
\(\delta(Zustand1,Eingabe1) = Zustand2\)
\(\delta(Zustand2,Eingabe1) = Zustand3\)
\(\delta(Zustand3,Eingabe1) = Zustand3\)
...
Der Kaugummi-Automat

- Ordne zu: Was sind die Zustände, was sind die Zustandsübergänge / Eingaben des Automaten.
- Drehknopf freigeben
- Kaugummi wird entnommen
- 10 Cent werden eingeworfen
- Drehknopf wird gedreht
- Warten auf Geldeingabe
- Kaugummi wird ausgegeben
- Erstelle die Zustandsübergangsfunktion des Automaten als Tabelle. Gib zusätzlich den Startzustand, den Endzustand und das Alphabet an.
- Welcher Zustand ist ein sinnvoller Startzustand deines Automaten?
- Überführe den von dir erstellten Automaten in die Darstellung als Graph.
Zustände: Drehknopf freigeben, Kaugummi ausgeben, Warten auf Geldeingabe.
Zustandsübergänge: 10 Cent werden eingeworfen, Drehknopf wird gedreht, Kaugummi wird entnommen.
-
Startzustand: S=Warten auf Geldeingabe
Endzustände: Entweder keiner oder F={Warten auf Geldeingabe}. Das hängt davon ab, ob eine Akzeptor oder ein Transitionssystem umgesetzt werden soll.
\(\delta(q,x)\) Warten auf Geldeingabe Drehknopf freigeben Kaugummi ausgeben 10 Cent werden eingeworfen Drehknopf freigeben - (unmöglich) Drehknopf freigeben Drehknopf wird gedreht Warten auf Geldeingabe Kaugummi ausgeben - (unmöglich) Kaugummi wird entnommen Warten auf Geldeingabe - (unmöglich) Warten auf Geldeingabe - Warten auf Geldeingabe

Automat auswerten
Notiere, was folgender Autoamt beschreibt.
S={Tür geschlossen}
F={}
\(\Sigma\)={Taste gedrückt, Sensor erreicht}
| \(\delta(q,x)\) | Tür offen | Tür geschlossen | Tür wird geöffnet | Tür wird geschlossen |
|---|---|---|---|---|
| Taste gedrückt | Tür wird geschlossen | Tür wird geöffnet | Tür wird geöffnet | Tür wird geschlossen |
| Sensor erreicht | Tür offen | Tür geschlossen | Tür offen | Tür geschlossen |
Es wird eine automatische Türsteuerung beschrieben. Dabei kann ein Schalter dazu verwendet werden, die Türe zu öffnen oder zu schließen.
Da das Öffnen bzw. das Schließen der Tür ein wenig Zeit braucht, befindet sich der Automat dann in einem jeweils entsprechenden Zustand. Dieser reagiert nicht mehr auf den Taster. Werden allerdings die Sensoren erreicht, wenn die Tür ganz offen / geschlossen ist, so wird der Taster wieder aktiviert.
Formalen Automat deuten
Notiere, was folgender Autoamt beschreibt.
Die Eingaben sind als binäre Zahlen (also Folgen von 0 und 1, z.B. 10010 oder 110101) zu interpretieren. Versuche ein Muster in den akzeptierten Wörtern zu erkennen und den Automat zu deuten.
S={A}
F={B}
\(\Sigma\)={0,1}
| \(\delta(q,x)\) | A | B |
|---|---|---|
| 0 | A | A |
| 1 | B | B |
Der Automat akzeptiert die formale Sprache: L={w | w endet auf 1}. Rechnet man die binäre Zahlen die auf 1 enden wieder ins Dezimalsystem um, so sind das die ungeraden Zahlen die durch diesen Automat erkannt werden.
Deterministische endliche Automaten
Worterkennung mit Automaten
In der Informatik werden Automaten oft verwendet, um Zeichenfolgen auf ihre Plausibilität hin zu überprüfen. Ein Automat bekommt eine Eingabe eines Wortes, das dann Zeichen für Zeichen gelesen wird.
Als Beispiel dient folgender Automat:

- Der Automat hat 4 Zustände (von \(q_0\) bis \(q_3\)), davon einen Anfangs- und einen Endzustand.
- Als Eingabealphabet erhält er die Buchstaben c,e und g.
- Der Automat akzeptiert zum Beispiel die Wörter cgcgggcgeeeee bzw. cccgeggge. Ein Wort wird von einem Automaten akzeptiert, wenn sich der Automat nach einlesen des letzten Zeichens in einem Endzustand befindet.
Automat analysieren
Welche Wörter akzeptiert der obige Automat noch? Gib die vom Automaten erkannte formale Sprache an.
Der Automat erkennt alle Wörter bestehend aus den Zeichen c,e und g, welche das Teilwort cge enthalten. Also die erkannte Sprache ist: L={ w | w enthält das Teilwort cge}.
Deterministischer endlicher Automat (DEA)
Formal werden in der Informatik deterministische endliche Automaten (DEA) als 5 Tupel charakterisiert mit: DEA = (Q, Σ, δ, S, F)
- Q ist die endliche Menge der Zustände eines Automaten (z.B. Q = {\(q_0, q_1, q_2, q_3\)})
- Σ Sigma, ist das endliche Eingabealphabet (z.B. Σ = {c, g, e}))
- F ist die Menge aller Endzustände und Teilmenge von Q (z.B. F = {\(q_3\)})
- S ist der Startzustand und Element von Q (z.B. S=\(q_0\)).
- δ Delta, ist die Übergangsfunktion, d.h. ein Zustand geht mittels einer Eingabe des Alphabets in einen anderen Zustand über; formal: Q x Σ → Q .
Hinweise zur Definition:
- Dies ist ein deterministischer Automat, da in jedem Zustand festgelegt ist, welches der nächste Zustand bei Eingabe einer bestimmten Anweisung aus dem Eingabealphabet ist. Der Automat befindet sich immer in einem eindeutigen Zustand.Bei nichtdeterministischen Automaten ist dies nicht der Fall. Die gleiche Anweisung kann in mehreren Zuständen enden (NEAs werden später behandelt).
- Da die Zustandsmenge endlich ist, wird auch der Automat endlich genannt. Die akzeptierten Sprachen können jedoch unendlich groß sein. Siehe obiges Beispiel.
- Ein Automat darf nur einen einzigen Startzustand, aber beliebig viele Endzustände haben.
- Die Übergangsfunktion Delta kann als Graph oder Tabelle übersichtlich dargestellt werden.
Das Wortproblem
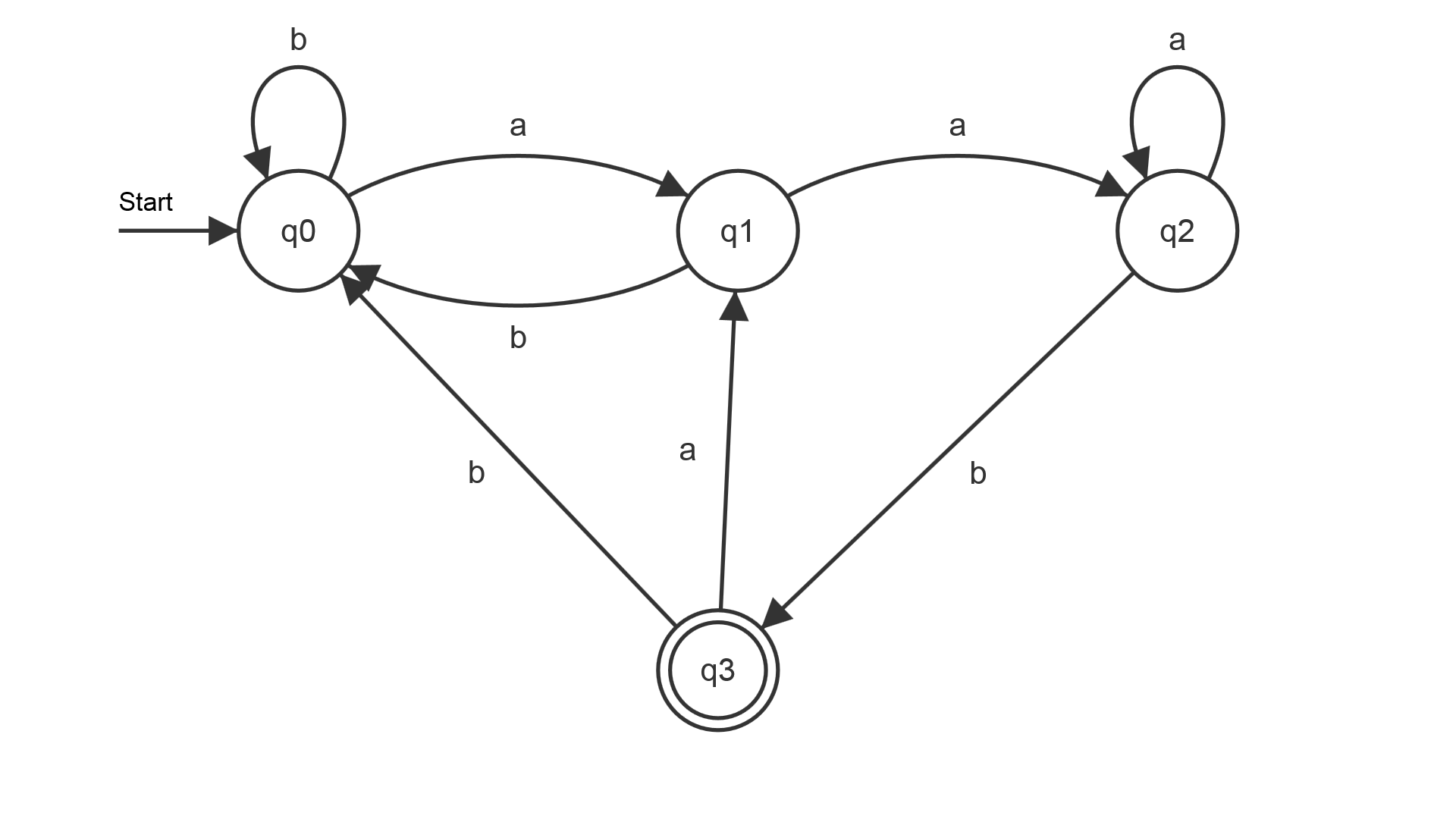
Die Frage, ob ein Wort in einer Sprache enthalten ist, kann leicht überprüft werden. Dafür wird das Eingabewort in die Eingabezeichen zerlegt. Beginnend vom Startzustand werden dann die jeweiligen Folgezustände besucht. Endet das Wort in einem Endzustand, so wird es akzeptiert. Für den Automaten wird überprüft ob die Wörter aabaa bzw. babaaab akzeptiert werden. Als Schreibweise wird die sogenannten Zustandsfolge verwendet:
- \(q_0 \underrightarrow{\textrm{ a }} q_1 \underrightarrow{\textrm{ a }} q_3 \underrightarrow{\textrm{ b }} q_1 \underrightarrow{\textrm{ a }} q_2 \underrightarrow{\textrm{ a }} q_1 \). Da \(q_1\) kein Endzustand ist, wird das Wort nicht akzeptiert.
- \(q_0 \underrightarrow{\textrm{ b }} q_0 \underrightarrow{\textrm{ a }} q_1 \underrightarrow{\textrm{ b }} q_0 \underrightarrow{\textrm{ a }} q_1 \underrightarrow{\textrm{ a }} q_2 \underrightarrow{\textrm{ a }} q_2 \underrightarrow{\textrm{ b }} q_3 \). Da \(q_3\) ein Endzustand ist, wird das Wort akzeptiert.
Wortproblem
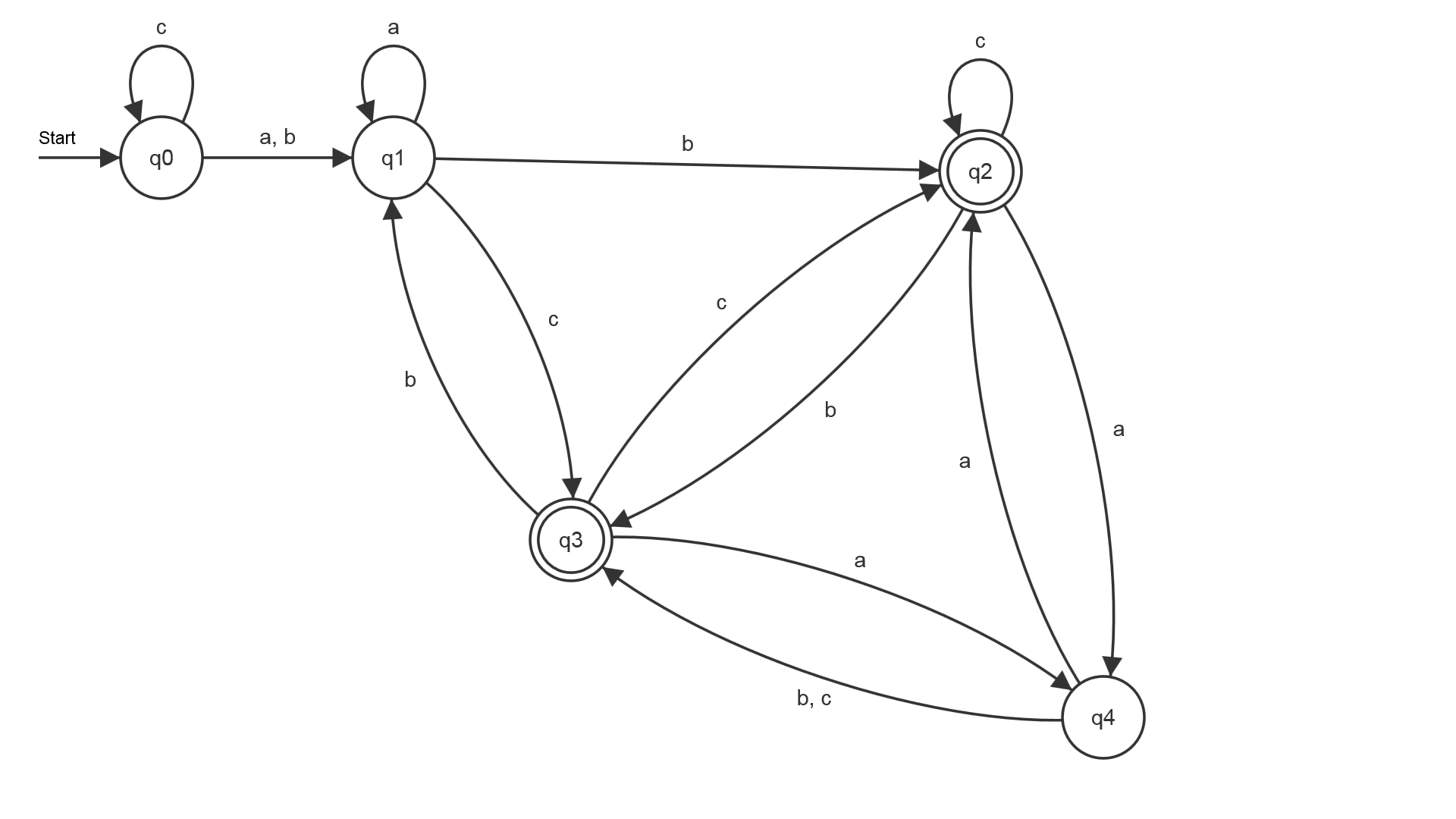
- Gib die Menge der Zustände des Automaten, den Startzustand, die Endzustände sowie das Eingabealphabet an.
- Leite aus den folgenden Eingabewörtern den jeweiligen Zustand ab, in welchem sich der Automat nach der Bearbeitung befindet.
- Wird das Wort cccabaaccaacc akzeptiert?
- Q={\(q_0,q_1,q_2,q_3,q_4\)} S=\(q_0\) F={\(q_2,q_3\)} \(\Sigma\)={a,b,c}
-
Im folgenden steht die Zustandsfolge.
- \(q_0 \underrightarrow{\textrm{ a }} q_1 \underrightarrow{\textrm{ b }} q_2 \underrightarrow{\textrm{ c }} q_2 \underrightarrow{\textrm{ b }} q_3 \underrightarrow{\textrm{ b }} q_1 \). Da \(q_1\) kein Endzustand ist, wird das Wort nicht akzeptiert.
- \(q_0 \underrightarrow{\textrm{ a }} q_1 \underrightarrow{\textrm{ b }} q_2 \underrightarrow{\textrm{ c }} q_2 \underrightarrow{\textrm{ b }} q_3 \underrightarrow{\textrm{ c }} q_2 \underrightarrow{\textrm{ b }} q_3 \underrightarrow{\textrm{ b }} q_1 \). Da \(q_1\) kein Endzustand ist, wird das Wort nicht akzeptiert.
- \(q_0 \underrightarrow{\textrm{ a }} q_1 \underrightarrow{\textrm{ a }} q_1 \underrightarrow{\textrm{ b }} q_2 \underrightarrow{\textrm{ b }} q_3 \underrightarrow{\textrm{ a }} q_4 \underrightarrow{\textrm{ a }} q_2 \). Da \(q_2\) ein Endzustand ist, wird das Wort akzeptiert.
- Zustandsfolge: \(q_0 \underrightarrow{\textrm{ c }} q_0 \underrightarrow{\textrm{ c }} q_0 \underrightarrow{\textrm{ c }} q_0 \underrightarrow{\textrm{ a }} q_1 \underrightarrow{\textrm{ b }} q_2 \underrightarrow{\textrm{ a }} q_4 \underrightarrow{\textrm{ a }} q_2 \underrightarrow{\textrm{ c }} q_2 \underrightarrow{\textrm{ c }} q_2 \underrightarrow{\textrm{ a }} q_4 \underrightarrow{\textrm{ a }} q_2 \underrightarrow{\textrm{ c }} q_2 \underrightarrow{\textrm{ c }} q_2 \). Da \(q_2\) ein Endzustand ist, wird das Wort akzeptiert.
Arbeiten mit merkwürdigen Alphabeten
In der theoretischen Informatik ist der Begriff Alphabet nicht direkt mit dem Alphabet vergleichbar was du normalerweise kennst. Denn neben Alphabeten aus Buchstaben werden auch Alphabete aus Zahlen, Wörtern, mathematischen Ausdrücken und so weiterverwendet. So zum Beispiel bei folgendem Automaten.
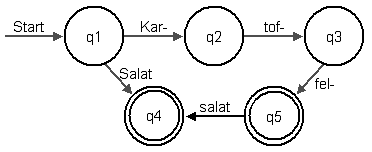
- Warum handelt es sich streng genommen bei dem Automaten in Abbildung 1 nicht um einen DEA? Viele Bücher und Informatiker verwenden diese Schreibeweise trotzdem für einen DEA. Dabei wurde festgelegt, dass fehlende Übergänge dazu führen, dass ein Wort nicht akzeptiert wird. Zum Beispiel Karfel. Von q1 nach q2 kommt man mit Kar. Von q2 gibt es aber keinen Übergang mit der Beschriftung fel. Daher wird Karfel nicht akzeptiert. Man landet in einer sogenannten Senke. Einem Zustand auf den nur Pfeile zeigen, aber keine davon ausgehen. Es gibt kein Entkommen, wenn man einmal in diesem Zustand gelandet ist.
- Bestimme alle Wörter, die durch den Automaten in Abbildung 1 akzeptiert werden.
- Nicht in jedem Zustand ist festgelegt, was bei jeder Ausgabe passiert. Zum Beispiel: Was passiert im Zustand q1 bei Eingabe von tof?
- L = { Salat, Kartoffel, Kartoffelsalat }
Sei Kreativ: Ein eigener Automat
- Erfinde einen eigenen Automaten, mit allen relevanten Angaben:
- Eingabealphabet
- Zustände
- Startzustand / Endzustände
- Übergangsfunktion als Graph oder Tabelle
- Eventuell: Bedeutung des Automaten. Welche Sprache wird erkannt?
- Erfinde 2 eigene Aufgaben zu deinem Automaten. (Wird das Wort w=… erkannt, welche formale Sprache wird erkannt,…)
- Suche dir einen Mitschüler bzw. eine Mitschülerin die auch diese Aufgabe bearbeitet und lasse ihn / sie deine Aufgabe bearbeiten. In dieser Zeit kannst du die Aufgaben deines Mitschülers bzw. deiner Mitschülerin bearbeiten.
Üben mit Exorciser
Exorsicer
Exorsicer ist ein tolles Übungsprogramm zu vielen Themen im Zusammenhang mit formalen Sprachen, insbesondere der Erstellung von Automaten.
- Lade Exorciser von https://www.swisseduc.ch/informatik/exorciser/classes/exorciser-de-3.10.jar runter.
- Starte die jar-Datei. Erlaube dazu entweder in den Einstellungen der Datei ein Ausnahmeregel oder verwende den Konsolen-Befehl java -jar exorciser_de.jar in Linux.
- Übungen zur Automatenkonstruktion findest du unter Theoretische Informatik -> Reguläre Sprachen -> Automatenkonstruktion
- Es öffnet sich das Übungsfenster und du kannst direkt mit den Übungen beginnen. Eine kurze Anleitung zur Steuerung des Programms findest du unter dem Knopf Anleitung. Durch „Antwort überprüfen“ erhältst du direkt eine Auswertung deiner Arbeit.
- Übe damit so lange du es für nötig hältst. Beachte dabei, dass du auch fortgeschrittene Aufgaben wählen kannst. Die sind allerdings knifflig.
Implementation DEA (Bonus)
Ziel ist die Erstellung eines allgemeinen deterministischen endlichen Automaten. Dieser soll in der Lage sein, jeden beliebigen Automaten darzustellen und das Wortproblem, also die Frage ob ein Wort in der Sprache L enthalten ist, auszuwerten.
Das Aufrufen der Methoden check("aaba") bzw. check("aabbbaaa") soll zu folgender Ausgabe führen:
q0 -a-> q0 -a-> q0 -b-> q1 -a-> q0. aaba nicht akzeptiert! q0 -a-> q0 -a-> q0 -a-> q0 -a-> q0 -a-> q0 -a-> q0 -a-> q0. aaaaaaa nicht akzeptiert! q0 -a-> q0 -b-> q1 -a-> q0 -b-> q1 -a-> q0 -b-> q1 -a-> q0. abababa nicht akzeptiert! q0 -a-> q0 -a-> q0 -b-> q1 -b-> q2 -b-> q3 -a-> q3 -a-> q3 -a-> q3. aabbbaaa akzeptiert!
Die Implementation eines endlichen Automaten ist relativ einfach. Ein Automat besteht aus Zuständen. Die Zustände haben wiederrum Übergänge, welche in einer Hashmap verwaltet werden können. Zur Darstellung soll für jeden Zustand noch ein Name sowie die Endzustandseigenschaft gespeichert werden.
Klassendiagramm.
Entwerfe ein Klassendiagramm unter Beachtung obiger Vorgaben.
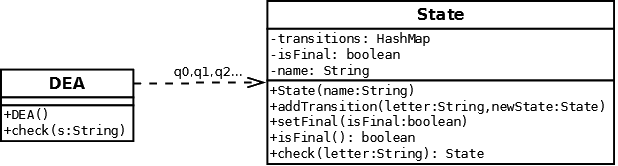
Die Klasse State
Jeder Zustand verwaltet neben seinem Namen und der isFinal Eigenschaft noch eine Zuordnung: Für jede mögliche Eingabe wird der Folgezustand gespeichert. Ist der Folgezustand in der Hashmap enthalten, so wird dieser zurückgegeben. Die Automatenklasse zurückgegeben, welcher später implementiert wird, kann dann von diesem Zustand aus weitere Entscheidungen treffen. Ist die Eingabe nicht in der transitions Hashmap enthalten, dann wird null zurückgegeben.
Eine Hashmap ist eine Menge von Schlüssel-Wert Paaren. Zu jedem Schlüssel wird der passende Wert gespeichert. Der Vorteil gegenüber einem Array: Die Schlüssel können beliebige Objekte (also Buchstaben, Texte, ...) sein und müssen keine numerischen Indizes [0],[1],[2],[3],[4],... sein !
| key k | value v |
|---|---|
| a | Zustand0 |
| b | Zustand0 |
| c | Zustand1 |
Obige Tabelle zeigt die Hashmap eines Zustands. Welches Alphabet wird verwendet und wie deutet man diese Tabelle? Das Alphabet sind die Zeichen a,b und c. Vom aktuellen Zustand kommt man mit einem a in Zustand 0, mit einem b ebenfalls in Zustand0 und mit einem c wechselt man den Zustand in Zustand1.
Tipps: Zur Hashmap
- Deklaration einer leeren Hashmap, welche als Schlüssel Strings und als Werte Objekte der Klasse State verwaltet:
HashMap < String, State > transitions;
- Beachte die Dokumentation der Klasse HashMap.
Klasse State
Implementiere die Klasse State.
import java.util.HashMap;
import java.util.Map;
/**
* Write a description of class Zustand here.
*
* @author Tim Schellartz
* @version 13.11.2020
*/
public class State {
private HashMap transitions; //Zustandsübergänge
private boolean isFinal; // true falls Endzustand
private static int counter = 0; //Zähler zur automatischen Bennenung der Zustände
private String name; //Name des Zustands
public State() {
name = "q" + counter;
counter++;
transitions = new HashMap();
isFinal = false;
}
/**
* Fügt einen Zustandsübergang hinzu.
* @param letter Zeichen des ÜBergangs
* @param newState Neue Zustand
*/
public void addTransition(String letter, State newState) {
transitions.put(letter, newState);
}
/**
* Setzt die Endzustandseigenschaft
* @param isFinal true, falls Endzustand
*/
public void setFinal(boolean isFinal) {
this.isFinal = isFinal;
}
/**
* Ist dieser Zustand ein Endzustand?
* @return true, falls Endzustand
*/
public boolean isFinal() {
return isFinal;
}
/**
* Liefert den nächsten Zustand anhand des aktuellen Zeichens
* @param letter aktuelles Zeichen
* @return Neuer Zustand. Null, falls es keine neuen Zustand gibt (Senke!)
*/
public State check(String letter) {
return transitions.get(letter);
}
/**
*
* @return Name des Zustands
*/
public String toString() {
return name;
}
}
Klasse DEA
Implementiere die Klasse DEA. Verwende die Klasse State aus der vorherigen Aufgabe um die entsprechenden Zustände und Übergänge zu erzeugen. Die Methode check zerlegt das Eingabewort in Buchstaben und prüft dann, welche neuen Zustände entstehen. Dies kann zur Auswertung genutzt werden, ob das Wort in der vom Automaten erkannten formalen Sprache enthalten ist, verwendet werden.
public class DEA {
State q0;
State q1;
State q2;
State q3;
public DEA(){
q0 = new State();
q1 = new State();
q2 = new State();
q3 = new State();
q3.setFinal(true);
q0.addTransition("a", q0);
q0.addTransition("b", q1);
q1.addTransition("a", q0);
q1.addTransition("b", q2);
q2.addTransition("a", q0);
q2.addTransition("b", q3);
q3.addTransition("a", q3);
q3.addTransition("b", q3);
}
/**
* Prüft ob ein Wort vom DEA akzeptiert wird und gibt die Zustandsfolge aus
* @param s Wort
*/
public void check(String s){
char[] letters = s.toCharArray();
State current = q0;
String out = current.toString();
for(char letter : letters){
current = current.check(""+letter);
if(current==null){
//Senke erreicht
out = out + (" -> Senke");
break;
}else{
out = out + (" -> "+current);
}
}
if(current != null && current.isFinal()){
out = out+". "+s+" akzeptiert!";
}else{
out = out+". "+s+" nicht akzeptiert!";
}
System.out.println(out);
}
public static void main(String[] args){
DEA d = new DEA();
d.check("aaba");
d.check("aaaaaaa");
d.check("abababa");
d.check("aabbbaaa");
}
}
Reguläre Ausdrücke
Reguläre Ausdrücke als Kurzschreibweise
Reguläre Ausdrücke sind neben Akzeptoren (Automaten mit Endzuständen) eine weitere Möglichkeit reguläre Sprachen darzustellen. Hat man die etwas gewöhnungsbedürftige Schreibweise regulärer Ausdrücke einmal verstanden, so bieten diese eine sehr schnelle Möglichkeit formale Sprachen kompakt zu beschreiben. Dies kann dann zum Beispiel zur Textanalyse verwendet werden, wenn man aus einem langen Textdokument die darin enthaltenen Telefonnummern filtern möchte.
Regex
Bei Regex geht es um Mustererkennung, wobei meist selbst im Deutschen eher vom Pattern Matching gesprochen wird. Ein Muster ist hier eine bestimmte Kette von Zeichen – mit einigen Unsicherheiten. Das Wort „Meier“ in einem Text oder Tausenden von Texten zu finden, ist kein Problem. Alle unterschiedlichen Schreibweisen von Meier zu finden und dabei Dinge wie „Schmidt-Meier“ oder „Herumeiern” auszuschließen oder nur „Mirca“ Meier zu matchen, aber durchaus.
Reguläre Ausdrücke lösen genau dieses Problem. Es ist eine Möglichkeit, in einem Text so ziemlich alles per Software zu finden, was auch ein Mensch finden kann. Und nach dem Finden kann man es natürlich auch verarbeiten. So ließen sich zum Beispiel alle wie auch immer geschriebenen Meiers in einer Adressdatenbank nach Schmidt umbenennen oder auch E-Mail-Adressen aus riesigen Textbeständen extrahieren.
Wenn ein Mediacenter wie Kodi eine Medienbibliothek aufbaut und dazu aus den vorhandenen Dateien Einträge wie „Serie XY Staffel 02 Episode 22“ erstellt, läuft auch das über Regular Expressions, die Dateinamen (im Wesentlichen) nach Mustern wie „s02_e22“ durchsuchen. Dort werden dann 2 und 22 für Staffel und Episode extrahiert und für die Suche in Online-Filmdatenbanken genutzt.
Reguläre Ausdrücke erstellen - die Meiers finden
Reguläre Ausdrücke bestehen aus unterschiedlichen Bestandteilen. Definitionen von Zeichen (a und/oder b), Quantifizierern (*, {min, max},? etc.), Platzfreihaltern (. für beliebige Zeichen), Steuerzeichen (\. für das Zeichen „Punkt“).
Um mal mit einem ganz einfachen Beispiel anzufangen: Angenommen, du hast eine heiratswütige Anverwandte, die mal „Mirca Schmidt Meier“, mal „Mirca Müller Meier“ und mal „Mirca Fischer Meier“ geheißen hat. Wenn du nun alle Versionen finden willst:
Mirca.*Meier
Der Platzhalter . steht für ein beliebiges Zeichen, der Quantifizierer * für eine beliebige Menge; es wird also alles gefunden, was mit Mirca anfängt und mit Meier aufhört – auch „123Mirca456Meier789“ würde gefunden. Wenn nun nicht beliebig viele beliebige Zeichen zwischen Mirca und Meier stehen dürfen, sondern nur drei bis fünf Zahlzeichen:
Mirca[0-9]{3,5}Meier
In eckigen Klammern werden Zeichenklassen angegeben, häufig zum Beispiel [A-Za-z0-9] für alle Buchstaben und Ziffern – und damit es nicht zu einfach wird, gibt es für viele Zeichenklassen auch Abkürzungen, beispielsweise \d für Ziffern (digits), wobei der Backslash grundsätzlich als Escape-Zeichen genutzt wird.
Möchtest du also ein Regex-Steuerzeichen wie den Punkt oder eine Klammer wörtlich finden, muss du jeweils \. beziehungsweise \( nutzen. Der Backslash ist zum Lesen von Regexen das vielleicht wichtigste Zeichen. Quantifizierer in Form von Bereichen werden in geschweiften Klammern angegeben. Überlege, was ...
Mirca\.{1}Meier
... bedeutet? Gefunden würde hier ausschließlich „Mirca.Meier“, weil genau ein wörtlicher Punkt zwischen Mirca und Meier stehen darf. Das {1} ließe sich auch als ? schreiben – beides überflüssig, da ein einzelnes Vorkommen der Standard ist. „Mirca...Meier“ würde man entsprechend via \.* finden.
Damit ist der grundsätzliche Aufbau einer Regex klar.
Regex101.com
Die Webseite regex101.com ermöglicht das einfache Testen von regulären Ausdrücken. Verwende dies um ein paar reguläre Ausdrücke zu testen.
Regex für Mirca Meier
Entwerfe einen reguläre Ausdruck, welcher alle oben erwähnten Varianten von Mirca Meier erfasst, aber keine Dinge wie Mirca456Meier.
Mirca [a-zA-Z-]* ?Meier
- [a-zA-Z-] steht für alle Buchstaben sowie das Minus (Doppelnachname wie Schmitz-Stolz)
- Der Stern beschreibt, dass die vorherigen Zeichen beliebig oft, also auch keinmal drankommen können.
- ? steht bezieht sich auf das Leerzeichen. Dies kann vorkommen oder nicht.
- Mirca und Meier werden bilden den Rahmen.
Alternative Lösungen sind hier sehr wahrscheinlich. Wichtig ist, verschiedene Varianten per regex101 zu testen.
Mailadressen in großen Texten suchen
Das Internet stellt für Adresshändler eine Goldgrube dar. Zum einen geben viele Menschen ihre Adressen und Telefonnummern direkt ein, zum Beispiel bei Facebook. Praktischerweise sind diese dann direkt mit Interessen etc. verknüpft.
Zum anderen lassen sich Emails und Telefonnummern auch noch auf anderem Wege „gewinnen“. Dazu können große Texte eingelesen werden, zum Beispiel aus Zeitungen, Webseiten und ähnlichem. Ein solcher Beispieltext ist die leicht modifizierte Fassung von Gorge Orwells 1984. Öffne diesen Link und füge den Text in den "Test String" Teil von regex101.com ein.
Um zu sehen, wie einfach man alle Email-Adressen automatisch finden kann, ist es nun deine Aufgabe mit Hilfe eines regulären Ausdrucks alle Email-Adressen zu finden. Insgesamt sind es 5 Stück. Versuche den regulären Ausdruck so anzupassen, dass nur die 5 Email-Adressen gefunden werden.
Der komplette reguläre Ausdruck ist /\S+@\S+/gm
Durch kopieren des inneren Teils \S+@\S+ in regex101.com bekommst du eine Erläuterung.
Telefonnummern suchen
Diese Aufgabe verwendet ebenfalls die leicht modifizierte Fassung von Gorge Orwells 1984. Suche diesmal allerdings 5 Telefonnummern und achte darauf nur diese zu finden.
Tipp: Nicht alle Telefonnummern sind nach demselben Muster verfasst. Überlege daher zunächst, wie Telefonnummern üblicherweise notiert werden.
Der komplette reguläre Ausdruck ist /\+?[0-9]{3,}[/\- ][0-9]{3,}/gm
Durch kopieren des inneren Teils \+?[0-9]{3,}[/\- ][0-9]{3,} in regex101.com bekommst du eine Erläuterung.
Nichtdeterministische endliche Automaten
Idee NEA
Automaten können Aufgrund der Größe der Zustandsmenge und des Eingabealphabets sehr groß und unübersichtlich werden. Ein einfaches Beispiel ist ein Automat, welcher zur Filterung von Emails dient und alle Mails, welche das Schlüsselwort Viagra enthalten, erkennt. Der dazu passende DEA sieht folgendermaßen aus:

Viel übersichtlicher ist der Automat als nichtdeterministischer endlicher Automat.

Der Nichtdeterminismus zeigt sich bereits im Startzustand. Wenn dort ein V gelesen wird, gibt es 2 Möglichkeiten zu reagieren:
- Übergang in \(q_0\)
- Übergang in \(q_1\)
Der Automat muss also alle Wege testen. Endet ein Weg in einem Endzustand, dann wird das Wort akzeptiert. Endet kein Weg in einem Endzustand, dann ist das Wort nicht akzeptiert.
DEA = NEA
Obschon der NEA anders funktioniert und eventuell mächtiger als der DEA wirkt, kann man zeigen, dass jeder NEA in einen DEA überführt werden kann. Daher kann ein NEA nicht mehr als ein DEA. Oder um es etwas formaler zu sagen: Die Menge der von NEA und DEA erkannten formalen Sprachen ist gleich.
Arbeiten mit NEA
Gegeben ist der folgende NEA:

- Begründe, dass es sich nicht um einen DEA handelt.
- Beschreibe, wie man feststellen kann, ob ein Wort von diesem Automaten akzeptiert wird.
- Zeige, dass die Wörter salesman und command zur Sprache des Automaten gehören.
- Erweitere den Automaten, so dass zusätzlich das Wort men akzeptiert wird.
- Der Automat ist kein deterministischer endlicher Automat, weil es vom Zustand \(q_0\) mit dem Eingabezeichen m zwei Zustandsübergänge zu unterschiedlichen Folgezuständen gibt.
- Ein Wort wird von dem Automaten akzeptiert, wenn es beginnend mit den Startzustand \(q_0\) eine Zustandsfolge gibt, die im Endzustand \(q_3\) endet, wobei jedes Zeichen des Wortes einen Zustandsübergang bewirkt.

- Da es ein NEA ist, muss nur auf dem Übergang von \(q_1 \rightarrow q_2\) der Buchstabe e ergänzt werden.
Potenzmengenkonstruktion
Die Potenzmengenkonstruktion ist ein Werkzeug, um jeden NEA in einen DEA zu überführen. Dabei bleibt die von den Automaten erkannte formale Sprache gleich.
Sieh dir zur Erklärung folgendes Video an:
Potenzmengenkonstruktion
Überführe folgenden NEA in einen DEA indem du die Potenzmengenkonstruktion durchführst.
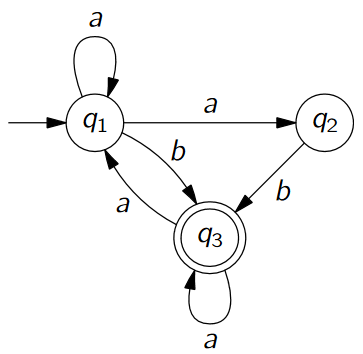
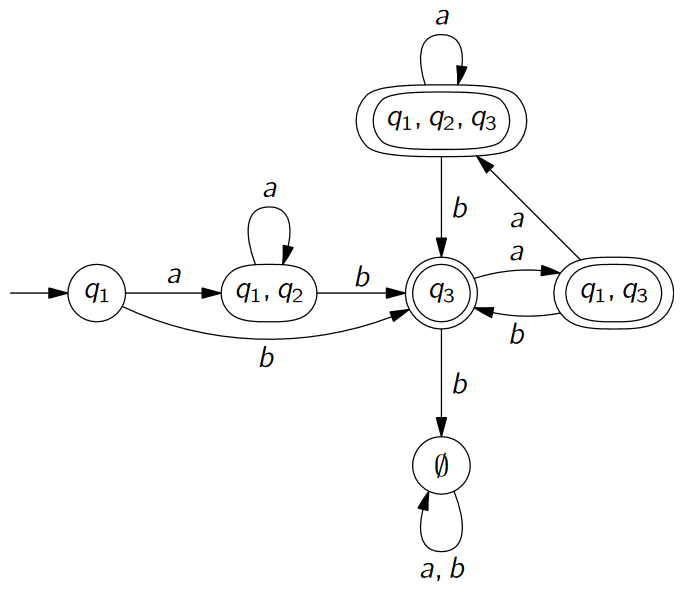
Potenzmengenkonstruktion
Überführe folgenden NEA in einen DEA indem du die Potenzmengenkonstruktion durchführst.
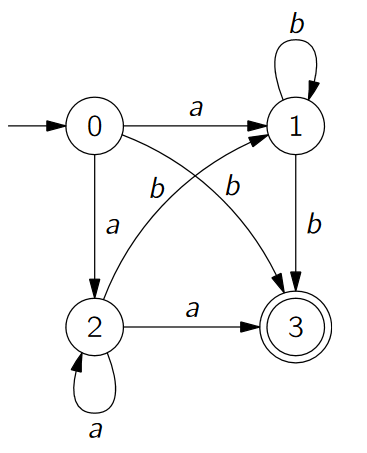
Üben mit Exorciser
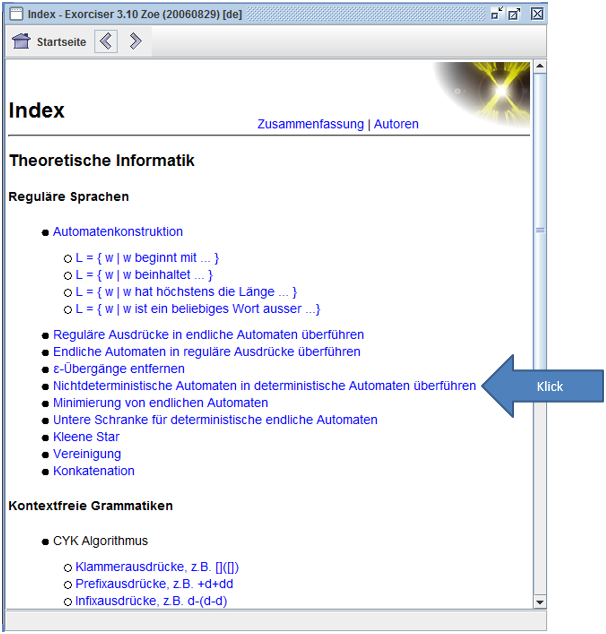
Zu diesem Themenbereich kannst du mit Exorciser üben! Wähle dazu einfach den Menüpunkt "Nichtdeterministische Automaten in deterministische Automaten überführen". Auch hier entscheidest du, wann du das Thema verstanden hast!
Implementation Nea (Bonus)
Idee
Die Implementation des nichtdeterministischen endlichen Automaten baut auf der Implementation des deterministischen endliche Automaten auf.
In der Klasse State muss lediglich anstatt eines einzelnen eine Menge von Folgezuständen je Zeichen speicherbar sein. Die Klasse NEA muss dann bei Untersuchung der Wörter ein Breitensuche durchführen.
State
Passe die Klasse für den Zustand so an, dass bei hinzufügen eines Zustands folgende Unterscheidung beachtet wird:
- Existiert das Zeichen noch nicht in der transitions Map, so wird eine neue ArrayListe von Folgezusänden gespeichert und diese in die Hashmap gepackt.
- Existiert das Zeichen schon in der Hashmap, dann wird lediglich der neue Zustand der bereits vorhandenen ArrayList hinzugefügt.
import java.util.HashMap;
import java.util.ArrayList;
/**
* Write a description of class Zustand here.
*
* @author Tim Schellartz
* @version 13..11.2020
*/
public class State {
private HashMap< String, ArrayList< State>> transitions; //Zustandsübergänge
private boolean isFinal; // true falls Endzustand
private static int counter = 0; //Zähler zur automatischen Benennung der Zustände
private String name; //Name des Zustands
/**
* Ein Zustand. Bezeichnung wird automatisch generiert von q0, q1,...
*/
public State() {
name = "q" + counter;
counter++;
transitions = new HashMap();
isFinal = false;
}
/**
* Fügt einen Zustandsübergang hinzu.
* @param letter Zeichen des Übergangs
* @param newState Neue Zustand
*/
public void addTransition(String letter, State newState) {
if(transitions.containsKey(letter)){
ArrayList< State > states = transitions.get(letter);
states.add(newState);
}else{
ArrayList< State > states = new ArrayList();
states.add(newState);
transitions.put(letter, states);
}
}
/**
* Setzt die Endzustandseigenschaft
* @param isFinal true, falls Endzustand
*/
public void setFinal(boolean isFinal) {
this.isFinal = isFinal;
}
/**
* Ist dieser Zustand ein Endzustand?
* @return true, falls Endzustand
*/
public boolean isFinal() {
return isFinal;
}
/**
* Liefert die nächsten Zustände anhand des aktuellen Zeichens
* @param letter aktuelles Zeichen
* @return Neue Zustandmenge als ArrayList. Null, falls es keine neuen Zustand gibt (Senke!)
*/
public ArrayList< State > check(String letter) {
return transitions.get(letter);
}
/**
*
* @return Name des Zustands
*/
public String toString() {
return name;
}
}
Breitensuche
Um nun alle Wege zu finden müssen alle Möglichkeiten überprüft werden. Dies kann rekursiv oder per Breitensuche geschehen. In diesem Beispiel betrachten wir die Breitensuche.
Pseudocode:
- Lege eine leere ArrayList current an.
- Füge den Startzustand in die ArrayList ein.
- Für jedes Zeichen des Eingabewortes:
- Lege eine leere ArrayList für die Folgezustände an.
- Für jeden Zustand in current:
- Lies alle Folgezustände next zum aktuellen Zeichen aus.
- Wenn next nicht null ist
- Überprüfe jeden Zustand in next und füge diesen nur hinzu, wenn dieser nicht schon enthalten ist.
Prüfe ob in der current ArrayList ein Endzustand enthalten ist. Falls ja, dann wird das Wort akzeptiert, sonst verworfen.
NEA
Implementiere die Klasse NEA nach obigem Beispiel. Im Vergleich zum DEA ändert sich nur die check Methode.
Die Lösung enthält noch eine aufbereitete Ausgabe.
import java.util.ArrayList;
/**
*
* @author Tim Schellartz
* @version 13.11.2020
*/
public class NEA {
State q0;
State q1;
State q2;
State q3;
public NEA(){
q0 = new State();
q1 = new State();
q2 = new State();
q3 = new State();
q3.setFinal(true);
q0.addTransition("a", q0);
q0.addTransition("a", q1);
q0.addTransition("b", q1);
q1.addTransition("a", q0);
q1.addTransition("b", q2);
q2.addTransition("a", q0);
q2.addTransition("b", q3);
q3.addTransition("a", q3);
q3.addTransition("b", q3);
}
/**
* Prüft ob ein Wort vom NEA akzeptiert wird und gibt die Zustandsfolge aus
* @param s Wort
*/
public void check(String text){
char[] letters = text.toCharArray();
ArrayList current = new ArrayList();
current.add(q0);
System.out.printf("Prüfe %s\n",text);
System.out.printf("Startzustand: %s\n",q0.toString());
// Prüfe jeden Buchstaben des Eingabewortes
for(char letter : letters){
ArrayList nextCurrent = new ArrayList();
// Durchlaufe jeden aktuellen Knoten
for(State s : current){
// Hole alle Folgezustände
ArrayList next = s.check(""+letter);
if(next!=null){
// Prüfe für jeden Folgezustand, ob dies schon enthalten
// ist und füge bei Bedarf hinzu.
for(State nextState : next){
if(!nextCurrent.contains(nextState)){
nextCurrent.add(nextState);
}
}
}
}
// Keine Nachfolger? Senke erreicht.
// Sonst Zustandsmenge printen
if(nextCurrent.isEmpty()){
//Senke erreicht
System.out.printf("Folgezustände für %s : Senke\n",letter);
break;
}else{
System.out.printf("Folgezustände für %s :",letter);
for(State s : nextCurrent){
System.out.print(" " + s);
}
System.out.println("");
}
current = nextCurrent;
}
boolean accepted = false;
// Prüfe ob ein Endzustand erreicht wurde
if(!current.isEmpty()){
for(State s : current){
if(s.isFinal()){
accepted = true;
}
}
}
if(accepted){
System.out.println(text + " wird akzeptiert.\n");
}else{
System.out.println(text + " wird nicht akzeptiert.\n");
}
}
public static void main(String[] args){
NEA d = new NEA();
d.check("aaba");
d.check("aaaaaaa");
d.check("abc");
d.check("aabbbaaa");
}
}
Reguläre Sprachen und ihre Grenzen
Chomsky-Hierarchie
Formale Sprachen werden anhand ihrer zulässigen Regeln in 4 verschiedene Hierarchiestufen eingeteilt:
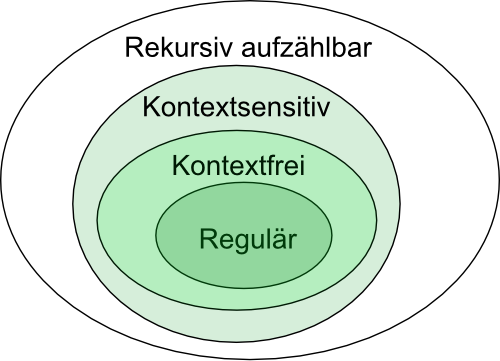
Die Struktur beschreibt, dass die spezielleren Sprachen (also z.B. reguläre Sprachen) auch immer mit den Regeln der allgemeineren Sprachen (also z.B. kontextfreie Sprachen) dargestellt werden können.
Bisher kennst du die Sprachen mit den striktesten Regeln: Reguläre Sprachen.
Reguläre Sprachen
Reguläre Sprachen sind die formalen Sprachen, welche von einem deterministischen endlichen Automaten erkannt bzw. einem regulären Ausdruck erzeugt werden können.
Aus der Definition wird klar: Ein Sprache ist nicht regulär, wenn wir keinen Automat erstellen können, welcher diese Sprache erkennt. Ein typisches und auch sehr simples Beispiel bearbeitest du in folgender Aufgabe.
Nicht reguläre Sprache
Begründe, warum die Sprache \(L=\{ a^n b^n |\) n ist eine beliebige natürliche Zahl\(\}\) nicht durch einen Automaten dargestellt werden kann.
Beispiele für Worte in der Sprache: ab, aabb, aaabbb, aaaabbbb
Auf den ersten Blick scheint ein passender Automat einfach konstruiert zu sein. Folgendes Bild zeigt den Automat welcher die Worte bis zur Länge 4 einliest:

Das Problem liegt darin, dass der Automat, welcher alle Worte der Sprache L erkennt, eine unendliche Anzahl Zustände bräuchte um die formale Sprache zu erkennen. Dies ist nicht erlaubt, daher ist diese Sprache nicht regulär.
Das Ergebnis aus der obigen Aufgabe lässt sich verallgemeinern: Deterministische endliche Automaten können nicht zählen ob Zeichen gleich oft vorkommen. Diese Einschränkung ist relativ stark. Zum Beispiel können auch Automaten nicht entscheiden, ob ein Programm oder ein mathematischer Ausdruck gleich viele öffnende wie schließende Klammern enthält. Dies ist aber eine wichtige Aufgabe eines Compilers.
Zusammenfassend:
- Jede reguläre Sprache kann durch einen DEA dargestellt werden.
- Das Wortproblem bei regulären Sprachen ist sehr effizient entscheidbar (lineare Komplexität).
- Reguläre Sprachen haben Grenzen: Zum Beispiel kann korrekte Klammerung nicht überprüft werden.
Kontextfreie Sprachen und Grammatiken
Grammatiken
Im vorherigen Kapitel wurde gezeigt, dass die regulären Sprachen strikte Grenzen haben. Kontextfreie Sprachen sind allgemeiner und können durch Grammatiken erzeugt werden. Diese sind flexibler als Automaten und können reguläre aber auch weitere Sprachen erzeugen, die sogenannten kontextfreien Sprachen. Allerdings ist das Wortproblem komplexer zu lösen und weniger effizient in der Auswertung.
Einfach gesagt bestehen Grammatiken aus Ersetzungsregeln, mit denen man Schritt für Schritt ein Element der gewünschten Sprache aufbauen kann. Außerdem bilden Grammatiken die Grundlage für Parser sowohl in der Verarbeitung natürlicher Sprachen als auch für Programmiersprachen.
kontextfreie Grammatik
Eine Grammatik zur Festlegung einer formalen Sprachen wird durch ein 4-Tupel (N,T,S,P) spezifiziert
- N ist die Menge der Nichtterminalsymbole. Die Nichtterminalsymbole deuten ihre Bedeutung schon im Namen an: Befindet sich noch mindestens ein Nichtterminalsymbol in dem aktuellen Wort, dann muss unter Verwendung der Produktionen weitergemacht werden. Man ist also erst dann fertig, wenn alle Nichtterminalsymbole entfernt wurden. Die Nichtterminalsymbole werden durch entsprechende Regeln in den Produktionen ersetzt. Nichtterminalsymbole werden zur besseren Lesbarkeit meist mit Großbuchstaben bezeichnet, z.B. \(N=\{S,A,B\}\)
- T ist die Menge der Terminalsymbole. Die Terminalsymbole sind die Zeichen (wie bei Automaten das Alphabet \( \Sigma \)) aus den die Wörter der formalen Sprache bestehen. Zur Besseren Unterscheidung werden diese in den Übungen meist mit Kleinbuchstaben bezeichnet, z.B. \(T=\{a,b\}\). Terminalsymbole können nicht weiter ersetzt werden.
- \(S \in N\) ist das Startsymbol. Beim Startsymbol beginnt die Erzeugung des Wortes.
- P ist die Menge der Regeln oder Produktionen. Die Produktionen sind Ersetzungsregeln für die Nichtterminalsymbole. Zum Beispiel bedeutet die Produktion \( A \rightarrow aA | a \), dass das Nichtterminalsymbol A entweder durch aA oder durch a ersetzt werden kann. Auf der linken Seite der Produktionen darf immer nur ein Nichtterminalsymbol stehen. | bedeutet oder.
Beispiel: Grammatik für einfache Sätze
Grammatiken geben Regeln an, wie ein Wort der Sprache aufgebaut ist. In der deutschen Sprache beispielsweise hat ein einfacher Satz die Struktur "Subjekt Prädikat Objekt." Ein Subjekt wiederum kann dabei ein Personalpronomen wie Ich und Du (am Anfang des Satzes groß geschrieben) oder auch ein Name, Laura oder Mats, sein. Ein Prädikat ist ein gebeugtes Verb, z. B. schreibe, siehst, lernst oder fährst. Objekte sind häufig kurze Wortgruppen wie den Mond, den Satz, die Formel oder das Auto.
Als formale Grammatik notiert:
G=(N,T,S,P)
N=(SATZ, SUBJEKT, PRONOMEN, NAME, PRÄDIKAT, OBJEKT)
T=(Ich, Du, Laura, Mats, schreibe, siehst, lernst, fährst, den Mond, den Satz, die Formel, das Auto)
S=SATZ
P={
- SATZ \( \rightarrow \) SUBJEKT PRÄDIKAT OBJEKT,
- SUBJEKT \(\rightarrow\) PRONOMEN ∣ NAME,
- PRONOMEN \(\rightarrow\) Ich ∣ Du,
- NAME \(\rightarrow\) Laura | Mats,
- PRÄDIKAT \(\rightarrow\) schreibe | siehst | lernst | fährst,
- OBJEKT \(\rightarrow\) den Mond | den Satz | die Formel | das Auto
}
Zum Beispiel kann der Satz "Du siehst den Mond" erzeugt werden. Dazu werden ausgehend vom Startsymbol Produktionen angewandt, bis der Satz darsteht:
| Satzform | Angewandte Regel |
|---|---|
| SATZ | SATZ \( \rightarrow \) SUBJEKT PRÄDIKAT OBJEKT |
| SUBJEKT PRÄDIKAT OBJEKT | SUBJEKT \( \rightarrow \) PRONOMEN |
| PRONOMEN PRÄDIKAT OBJEKT | PRONOMEN \( \rightarrow \) Du |
| Du PRÄDIKAT OBJEKT | PRÄDIKAT \( \rightarrow \) siehst |
| Du siehst OBJEKT | OBJEKT \( \rightarrow \) den Mond |
| Du siehst den Mond |
Eine weitere mögliche Darstellungsform ist der Ableitungsbaum:
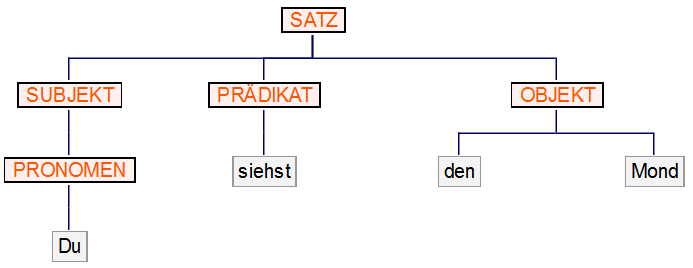
Grammatik für einfache Sätze
Finde eigene, durch die Grammatik erzeugte, Sätze.
Viele Möglichkeiten denkbar, davon sind die meisten nur syntaktisch, aber nicht semantisch korrekt.
- Mats schreibe den Mond
- Ich fährst den Mond
- Ich lernst die Formel
- Du lernst die Formel
Beispiel: Grammatik für die Sprache \(L=\{ a^n b^n |\) n ist eine beliebige natürliche Zahl\(\}\)
Die Sprache \(L=\{ a^n b^n |\) n ist eine beliebige natürliche Zahl\(\}\) kann durch eine sehr einfache kontextfreie Grammatik erzeugt werden:
G=(N,T,S,P)
N=(S)
T=(a,b)
P={
- S \( \rightarrow \) aSb | \( \epsilon \)
}
Das \( \epsilon \) ist ein Platzhalter für "das leere Wort" bzw. "nichts". Mit der Grammatik können alle Wörter erzeugt werden, welche beliebig viele, aber gleich viele a's und b's enthalten: Zum Beispiel aaaabbbb
| Satzform | Angewandte Regel |
|---|---|
| S | S \( \rightarrow \) aSb |
| aSb | S \( \rightarrow \) aSb |
| aaSbb | S \( \rightarrow \) aSb |
| aaaSbbb | S \( \rightarrow \) aSb |
| aaaaSbbbb | S \( \rightarrow \) \( \epsilon \) |
| aaaabbbb |
Grammatik
Gegeben ist folgende Grammatik:
G=(N,T,S,P)
N=(X,A)
T=(0,1)
S=X
P={
- X \( \rightarrow \) 1 | 1A,
- A \( \rightarrow \) 0 | X0
}
- Zeige, dass das die Worte 1100 und 11100 in der Sprache der Grammatik enthalten sind.
- Finde 2 weitere Worte, welche durch die Grammatik G erzeugt werden.
- Beschreibe in eigenen Worten, welche Worte durch die Sprache erzeugt werden.
-
Satzform Angewandte Regel X X \( \rightarrow \) 1A 1A A \( \rightarrow \) X0 1X0 X \( \rightarrow \) 1A 11A0 A \( \rightarrow \) 0 1100 Satzform Angewandte Regel X X \( \rightarrow \) 1A 1A A \( \rightarrow \) X0 1X0 X \( \rightarrow \) 1A 11A0 A \( \rightarrow \) X0 11X00 X \( \rightarrow \) 1 11100 - Individuelle Lösung: Zum Beispiel 1 und 10.
- L={w|w besteht aus beliebig vielen 1en gefolgt von gleich vielen oder eine weniger 0en}
Mehr Grammatik
Gegeben ist folgende Grammatik:
G=(N,T,S,P)
N=(A,B)
T=(a,b)
S=A
P={
- A \( \rightarrow \) aB | bA,
- B \( \rightarrow \) aB | bA | \( \epsilon \)
}
- Zeige, dass die Worte a, aaaa und baba durch die Grammatik G erzeugt werden.
- Finde 2 weitere Worte mit Mindestlänge 5, welche durch die Grammatik G erzeugt werden.
- Beschreibe in eigenen Worten, welche Worte durch die Sprache erzeugt werden.
-
Satzform Angewandte Regel A A \( \rightarrow \) aB aB B \( \rightarrow \) \( \epsilon \) a Satzform Angewandte Regel A A \( \rightarrow \) aB aB B \( \rightarrow \) aB aaB B \( \rightarrow \) aB aaaB B \( \rightarrow \) aB aaaaB B \( \rightarrow \) \( \epsilon \) aaaa Satzform Angewandte Regel A A \( \rightarrow \) bA bA A \( \rightarrow \) aB baB B \( \rightarrow \) bA babA A \( \rightarrow \) aB babaB B \( \rightarrow \) \( \epsilon \) baba - Zum Beispiel bbbba oder ababa
- L={w|w besteht aus a und b und das letzte Zeichen muss ein a sein.}
Reguläre Grammatiken
Da die regulären Sprachen eine Teilmenge der kontextfreien Sprachen sind, können diese auch durch Grammatiken erzeugt werden. Diese Grammatiken nennt man reguläre Grammatiken.
Die Umwandlung eines Automaten in eine dazu passende Grammatik ist ebenfalls einfach und kann durch folgendes Video nachvollzogen werden:
Automat in reguläre Grammatik
- Beschreibe die durch den Automaten akzeptierte formale Sprache.
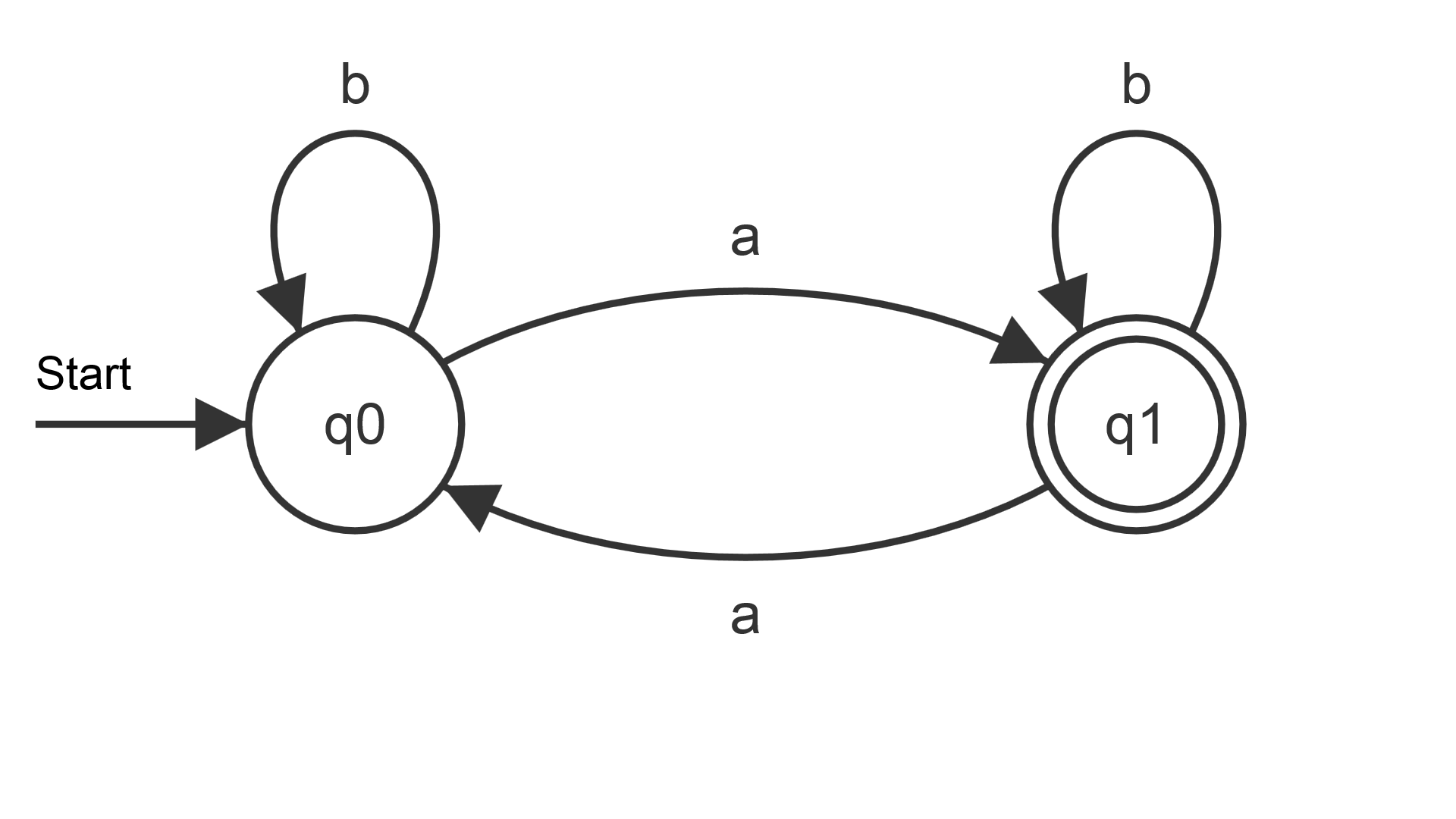
- Erstelle eine rechtsreguläre Grammatik, welche dieselbe Sprache wie der Automat erzeugt.
- L={ w | w enthält eine ungerade Anzahl a's}
G=(N,T,S,P)
N=(\(Q_0\),\(Q_1\))
T=(a,b)
S=\(Q_0\)
P={
- \(Q_0\) \( \rightarrow \) a\(Q_1\) | b\(Q_0\),
- \(Q_1\) \( \rightarrow \) a\(Q_0\) | b\(Q_1\) | \( \epsilon \)
}
Eine Mathematikgrammatik
Im ersten Kapitel hast du bereits über eine formale Sprache für Rechenterme nachgedacht und Regeln formuliert. ÜBerführe diese nun in eine passende Grammatik. Zur Erinnerung:
Entwickle eine kontextfreie Grammatik, durch die mithilfe der Zeichen (, ), +, –, ·,: und den Ziffern 0, 1, . . ., 9 syntaktisch korrekte Rechenterme beschrieben werden können. Diese sollen nur die vier Grundrechenarten inklusive Klammerung enthalten.
G=(N,T,S,P)
N=(TERM, OPERATOR, ZIFFER, ZAHL)
T=(0,1,2,3,4,5,6,7,8,9,+,-,*,/,(,),)
S=TERM
P={
- TERM \( \rightarrow \) ZAHL | ( TERM ) | TERM OPERATOR TERM,
- OPERATOR \( \rightarrow \) + | - | * | /,
- ZIFFER \( \rightarrow \) 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ZIFFER ZIFFER | \(\epsilon\),
- ZAHL \( \rightarrow \) 1 ZIFFER | 2 ZIFFER | 3 ZIFFER | 4 ZIFFER | 5 ZIFFER | 6 ZIFFER | 7 ZIFFER | 8 ZIFFER | 9 ZIFFER | 0
}
flaci.com (Bonusaufgabe)
Eigene Grammatiken kannst du auf der Webseite https://flaci.com/kfgedit eingeben und testen.
Die Eingabe und Verwendung wird unten erläutert. Ein Beispiel zum kopieren:
SATZ -> SUBJEKT PRÄDIKAT OBJEKT SUBJEKT -> PRONOMEN | NAME PRONOMEN -> Ich | Du NAME -> Laura | Mats PRÄDIKAT -> schreibe | siehst | lernst | fährst OBJEKT -> den Mond | den Satz | die Formel | das Auto
Einordnung und Ausblick: Kontextfreie vs. Kontextsensitive Sprachen
Entnommen von https://de.wikipedia.org/wiki/Kontextfreie_Sprache
In der Theoretischen Informatik ist eine kontextfreie Sprache eine formale Sprache, die durch eine kontextfreie Grammatik beschrieben werden kann. Eine kontextfreie Grammatik erlaubt einen definierten Leseprozess (Interpretation) von Ausdrücken einer formalen Sprache. Dabei kann zum einen entschieden werden, ob ein Ausdruck den Regeln der Grammatik entspricht, und zum anderen im Verlauf der Analyse ein Syntaxbaum erstellt werden. Ein Programm, das dies leistet, heißt Parser. Parser werden insbesondere zur Verarbeitung von Programmiersprachen verwendet. Auch in der Computerlinguistik versucht man, natürliche Sprachen durch Regeln kontextfreier Grammatiken zu beschreiben.
Kontextfreie Sprachen werden auch als Typ-2-Sprachen der Chomsky-Hierarchie bezeichnet. Die Klasse aller kontextfreien Sprachen beinhaltet die regulären Sprachen (Typ-3-Sprachen) und wird von der Klasse der kontextsensitiven Sprachen (Typ-1-Sprachen) umfasst.
Man spricht von kontextfreien Sprachen, weil die Regeln der kontextfreien Grammatiken immer vom Kontext unabhängig angewendet werden, da jeweils auf den linken Seiten der Produktionsregeln nur ein Nichtterminal stehen darf. Das unterscheidet sie von kontextsensitiven Grammatiken, deren Regeln auch vom syntaktischen Kontext abhängen, also auf den linken Seiten der Produktionsregeln auch Kombinationen von Nichtterminalen und Terminalen stehen dürfen.
Kontextfreie Sprachen finden in der Definition der Syntax von Programmiersprachen Anwendung, es lassen sich zum Beispiel arithmetische Ausdrücke und allgemein korrekte Klammerstrukturen festlegen. Grenzen der kontextfreien Sprachen liegen bei kontextrelevanten Eigenschaften, wie z. B. der Typüberprüfung in Programmiersprachen, die sich nur durch kontextsensitive Grammatiken darstellen lassen. In der Praxis verwendet man aber kontextfreie Parser mit zusätzlichen Funktionen und Datenstrukturen.
Beispiel kontextsensitive Sprache: \( L_3 = \{ a^n b^n c^n | n\in\mathbb{N}\}\). Dieses Problem sieht nicht wesentlich anders aus als die bisher behandelten, aber es ist unmöglich eine kontextfreie Grammatik dafür zu entwickeln.
Alte Abituraufgabe (Bonus)
Abituraufgabe 2019
Als Vorbereitung auf den Test oder die Klausur kannst du deine Fähigkeiten an der Abituraufgabe 2019 zum Themenbereich formale Sprachen testen. Passwort: Kürzel der Schule, kleingeschrieben. Die Lösungen findest du ebenfalls im pdf-Dokument.